Code
try:
import fysisk_biokemi
print("Already installed")
except ImportError:
%pip install -q "fysisk_biokemi[colab] @ git+https://github.com/au-mbg/fysisk-biokemi.git"v1.0.1
try:
import fysisk_biokemi
print("Already installed")
except ImportError:
%pip install -q "fysisk_biokemi[colab] @ git+https://github.com/au-mbg/fysisk-biokemi.git"import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from scipy.optimize import curve_fit
from fysisk_biokemi.widgets import DataUploader
from IPython.display import display
pd.set_option('display.max_rows', 6)Here, we will analyse the results from an experiment used to quantify affinity of a protein:lignd interaction. The data in binding_data_sq.xlsx is in the form of saturation (theta) as a function of the total ligand concentration L_tot. This is the type of data you typically get from e.g. a fluorescence titration experiment. Each measure-ment has been repeated three times.
Load the dataset as usual using the widget below
uploader = DataUploader()
uploader.display()Run the next cell after uploading the file
The command display(df) shows the dataframe that you’ve loaded.
df = uploader.get_dataframe()
display(df)Convert the ligand concentration to \(\mathrm{M}\) and add it to the dataframe as a new column named 'L_(m)'.
You can use display(df) to check if you have been successful.
# Your task: Add a column to the dataframe with the ligand concentration in M.
...Make a scatter plot of the dataset and use the plot to estimate \(K_D\).
fig, ax = plt.subplots()
## Your task: Make a scatter plot (just points, no lines) of the data. ##
...Put your estimate of \(K_D\) in the cell below
## Your task: Assign your estimate of K_D to the variable below ##
K_D_estimate = ...Fit the data using the simple binding expression
\[ \theta = \frac{[L]}{[L] + K_D} \]
Start by defining a function, called simple_binding, that calculates this expression
## Your task: Define the function simple_binding that evaluates the equation ##
## from above. ##
## Hint: It takes two inputs - the first has to be the independent variable.
def ...
...
...Then use that function to fit the data using curve_fit
## Your task: Set your estimate of K_D as the inital guess.
initial_guess = [...]
## Your task: Use curve_fit to find the fitted value of K_D
fitted_parameters, trash = ...
## This extracts K_D and prints it ##
K_D_fit_simple = fitted_parameters
print(K_D_fit_simple)And evaluate the fit and plot it together with the dataset
## Your task: Evaluate simple_binding using L_smooth and the value of K_D from your fit ##
L_smooth = np.linspace(0, 0.0005, 100)
theta_fit_simple = ...
fig, ax = plt.subplots()
## Your task: Plot the fit as line plot and the data as a scatter plot. ##
...
...Is it a good fit?
To get a more quantitative view of the quality of the fit calculate residuals
# Your task: Calculate the residuals by evaluating the fit at the measured datapoints
theta_model = ...
residuals_simple = ...And plot them versus the measured \(\mathrm{[L]}\)
fig, ax = plt.subplots()
## Your task: Make a plot with residuals on the y-axis and L on the x-axis ##
# This makes a horizontal line through 0
ax.axhline(0, color='black', linestyle='--')Are the residuals randomly distributed around zero? What does this tell you about the quality of the fit?
The protein concentration in the above titrations was 250 uM. Formulate a hypothesis for why the fit fails.
Next, we will try a fitting model that explicitly considers the concentration of the protein being titrated. This is known as the quadratic binding equation
\[ \begin{aligned} \theta &= \frac{K_D + [P_{tot}] + [L_{tot}]}{2[P_{tot}]} - \sqrt{\left(\frac{K_D + [P_{tot}] + [L_{tot}]}{2[P_{tot}]}\right)^2 - \frac{[L_{tot}]}{[P_{tot}]}} \\ \end{aligned} \]
The value of \([P_{tot}]\) is \(250 \ \mu\mathrm{M}\).
Start by implementing the expression as a Python function - remember that you need to be careful with parentheses with a function like this.
def quadratic_binding(L, K_D):
## Your task: Set the protein concentration in appropriate units. ##
P_tot = ...
## Your task: Implement the quadratic binding equation ##
## Be careful with parentheses! ##
theta = ...
return ...
print(f"{quadratic_binding(100, 138.09) = :.3f}") # Should give 0.420And now make a fit using this expression
## Your task: Make a fit using the quadratic binding equation. ##
fitted_parameters, trash = ...
## Extratcs and prints K_D ##
K_D_fit_quad = fitted_parameters[0]
print(K_D_fit_quad)The cell below makes a figure of the data and the residuals for each fit. You are not expected to understand every line of code – the figure is mainly to aid you interpretation of the data and show case how you can make beautiful figures from you own data later on.
theta_fit_quad = quadratic_binding(L_smooth, K_D_fit_quad)
residuals_quad = df['theta'] - quadratic_binding(df['L_(M)'], K_D_fit_quad)
fig, axes = plt.subplots(1, 2, figsize=(9, 4))
# Data & Fit
ax = axes[0]
ax.plot(df['L_(M)'], df['theta'], 'o', label='Data')
ax.plot(L_smooth, theta_fit_simple, label='Simple binding', linewidth=3)
ax.plot(L_smooth, theta_fit_quad, label='Quadratic binding', linewidth=3)
ax.set_xlabel('L (M)')
ax.set_ylabel(r'$\theta$')
ax.set_title('Data & Fits')
ax.legend()
# Residuals
ax = axes[1]
ax.plot(df['L_(M)'], residuals_simple, 'o', color='C1', label='Simple binding')
ax.plot(df['L_(M)'], residuals_quad, 'o', color='C2', label='Quadratic binding')
ax.axhline(0, color='black', linestyle='--')
ax.set_title('Residuals')
ax.set_xlabel('L (M)')
ax.legend()
plt.show()Consider the following questions:
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from scipy.optimize import curve_fit
from fysisk_biokemi.widgets import DataUploader
from IPython.display import display
pd.set_option('display.max_rows', 6)You have carried out a kinetic experiment investigating the turnover of two metabolites, A1 and A2, in a cell lysate. For each metabolite, you have measured the concentration of the compound as a function of time using UV-Vis spectroscopy aiming to determine the reaction order, and thus deduce something about the reaction mechanism by which they are processed. The date from this experiment is found in reaction-orders.xlsx.
Load the dataset reaction-orders.xlsx using the widget below
uploader = DataUploader()
uploader.display()Run the next cell after uploading the file
df = uploader.get_dataframe()
display(df)Add two new columns with the concentrations given in M.
## Your task: Add new columns with the A1_M and A2_M.
...
...
display(df)For each reactant make a plot of the concentration versus time.
fig, ax = plt.subplots()
## Your task: Make plots of concentration (y) versus time (x). ##
## Hint: ax.plot(x_data, y_data, 'o') to make a scatter plot.
...
...
## EXTRA: Customization of axis labels ##
ax.set_xlabel('Time [s]')
ax.set_ylabel('Concentration')We will model the reactions as zeroth, first and second order. We will consider both the the rate constant \(k\) and the concentration at time \(t = 0\) parameters of the fit.
def zeroth_order(t, k, A0):
## Your task: Implement the zeroth order rate equation ##
result = ...
return result
def first_order(t, k, A0):
## Your task: Implement the first order rate equation ##
result = ...
return result
def second_order(t, k, A0):
## Your task: Implement the second order rate equation ##
result = ...
return result
## Use these to check that your functions are correct!
print('zeroth_order', zeroth_order(1, 1, 2)) # Should give 1
print('first_order', first_order(1, 1, 2)) # Should give 0.7357...
print('second_order', second_order(1, 1, 2)) # Should give 0.4Then we can make a fit to measurements of each reactant.
## Your task: Pick a rate equation and assign it to the variable rate_equation
## You can change this to first_order or second_order
## Do not call the function - so no (...) just assign it to the variable.
rate_equation = ...
## Your task: Make a fit of the A1_M data with 'rate_equation'.
fitted_parameters_A1, trash = ...
k_A1_fit = fitted_parameters_A1[0]
A1_0_fit = fitted_parameters_A1[1]
## Your task: Make a fit of the A2_M with 'rate_equation'.
fitted_parameters_A2, trash = ...
k_A2_fit = fitted_parameters_A2[0]
A2_0_fit = fitted_parameters_A2[1]
## Prints the found parameters
print(k_A1_fit)
print(A1_0_fit)
print(k_A2_fit)
print(A2_0_fit)Now that we fitted the data using one of the rate equations, we can plot to see how well it fits
fig, ax = plt.subplots()
## Your task: Finish the code to calculate the fit for A2.
t_smooth = np.linspace(0, 55)
A1_fit = rate_equation(t_smooth, k_A1_fit, A1_0_fit)
A2_fit = ...
## Your task: Plot the fits
...
...
## Plots the data ##
ax.plot(df['Time_s'], df['A1_M'], 'o')
ax.plot(df['Time_s'], df['A2_M'], 'o')
## EXTRA: Customization of axis labels ##
ax.set_xlabel('Time [s]')
ax.set_ylabel('Concentration')Once you’ve finished the fitting with one of the rate equations you can go back and change the rate_equation variable to try one of the others.
The cell below makes a plot for each rate law in the same panel using your defined rate equations.
from fysisk_biokemi.utils.deter_reacti_orders import make_plot
rate_laws = {0: zeroth_order, 1: first_order, 2: second_order}
make_plot(df, rate_laws)Based on this plot;
What does the above tell you about the reaction mechanism whereby the two compounds disappear from the lysate?
import matplotlib.pyplot as plt
import numpy as npConsider the following reaction
\[ A \underset{k_{2}}{\stackrel{k_1}{\rightleftharpoons}} B \]
The magnitudes of the rate constants are \(k_1 = 10 \ \mathrm{s}^{-1}\) and \(k_2 = 1 \ \mathrm{s}^{-1}\).
What is the reaction order in each direction?
Show mathematically how the equilibrium constant \(K_{\mathrm{eq}}\) is given by the ratio between the two rate constants.
## Your task: Assign known values & calculate the equilibrium constant.
k1 = ...
k2 = ...
K_eq = ...
print(K_eq)Calculate the concentrations of A and B at equilibrium, \([\mathrm{A}]_{\mathrm{eq}}\) and \([\mathrm{B}]_\mathrm{eq}\), if \([\mathrm{A}]_0 = 10^{-3} \text{M}\)
## Your task: Assign known values and calculate the concentrations at equilibrium.
A0 = ...
A_eq = ...
B_eq = ...
print(A_eq)
print(B_eq)If \([\mathrm{A}]_0 = 10^{-3} \ \text{M}\) and \([\mathrm{B}]_0 = 0 \ \text{M}\), calculate the initial rate of formation of B.
## Your task: Calculate initial rate of formation of B
r_fwd = ...
print(r_fwd)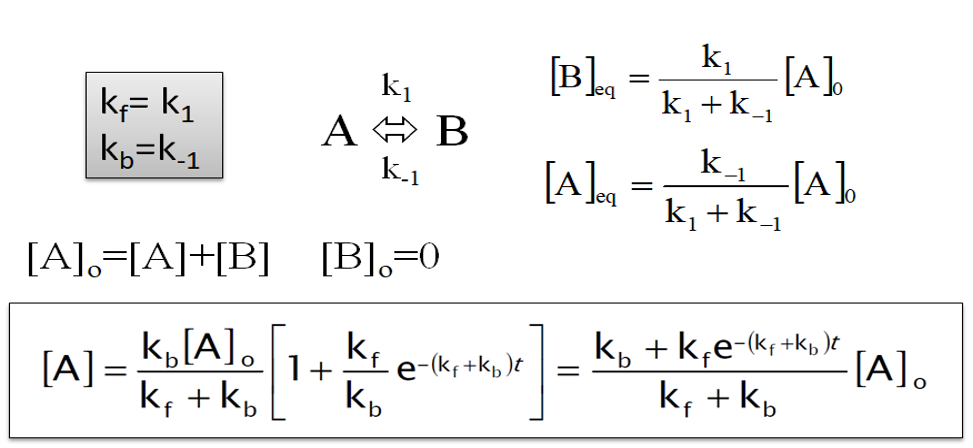
We now want to calculate and plot the time-dependent concentrations using the above equations.
In the cell below finish the implementation of the function A_time that calculates the concentration [A] as a function of time.
## Your task: Implement the function to calculate the time dependent concentration.
## Be careful with parentheses.
def A_time(t, A0, k_f, k_b):
A_t = ...
return A_t
test = A_time(1, 1, 1, 1)
print(test) # This should give 0.567...And then we can use that function to calculate and plot the concentrations as a function of time. As you have seen above, the reaction is pretty fast, so we will just focus on the first second
fig, ax = plt.subplots()
t = np.linspace(0, 1, 100)
## Your task: Calculate [A](t) and [B](t) ##
At = ... # Use your function to calculate [A](t)
Bt = ... # Calculate [B](t)
## Plots the concentrations versus time.
ax.plot(t, At, label='[A](t)')
ax.plot(t, Bt, label='[B](t)')
## EXTRA: Sets x and y-axis labels.
ax.set_ylabel('Concentrations (M)')
ax.set_xlabel('Time (s)')
ax.legend()import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from fysisk_biokemi.widgets import DataUploader
from IPython.display import display
from scipy.optimize import curve_fit
pd.set_option('display.max_rows', 6)The irreversible isomerization of compound A to compound B results in a decreasing absorbance. The isomerization was followed in a time course at two different temperatures (T1 = 25 °C and T2 = 40 °C). The absorbance (\(\epsilon\) = 16700 \(\mathrm{cm}^{-1} \mathrm{M}^{-1}\)) was used to calculate the concentration of compound A in a spectrophotometer with a pathlength of 1 cm. The obtained dataset is given in the file deter-reacti-order-activ.csv.
What are the two temperatures in Kelvin? Set them as varilabes in the cell below.
## Your task: Convert the temperatures to K and assign to the variables:
T1 = ...
T2 = ...Load the dataset using the widget below
uploader = DataUploader()
uploader.display()Run the next cell after uploading the file
df = uploader.get_dataframe()
display(df)Calculate the concentration of A at each timepoint in SI units, by adding new columns to the DataFrame.
## Your task: Assign known values ##
extinction_coeff = ...
L = ...
## Your task: Calculate concentrations using the variables above and the ##
## data in the dataframe ##
df['[A]_(M)_25C'] = ... # For 25 C
... # For 40 C
display(df)We will be resuing the plot, so we will put the code for it in a function.
fig, ax = plt.subplots()
# Task: Plot the two data series in a scatter plot
# That is: t_(s) vs [A]_(M)_25C
# and: t_(s) vs [A]_(M)_40C
ax.plot(..., ..., 'o', label='[A]_25C')
ax.plot(..., ..., 'o', label='[A]_40C')
## EXTRA: This sets x and y-axis labels and shows the legends.
ax.set_xlabel('t (s)')
ax.set_ylabel('[A] (M)')
ax.legend()Now want to fit the data using integrated rate laws - in order to ultimately determine the reaction orders of the two datasets.
To do so we need functions for zeroth, first and second order integrated rate laws.
def zeroth_order(t, k, A0):
## Your task: Implement the zeroth order rate equation ##
result = ...
return result
def first_order(t, k, A0):
## Your task: Implement the first order rate equation ##
result = ...
return result
def second_order(t, k, A0):
## Your task: Implement the second order rate equation ##
result = ...
return result
## Use these to check that your functions are correct!
print('zeroth_order', zeroth_order(1, 1, 2)) # Should give 1
print('first_order', first_order(1, 1, 2)) # Should give 0.7357...
print('second_order', second_order(1, 1, 2)) # Should give 0.4Having defined these functions we can use them for fitting
## Task: Choose one of the rate equations and assign to the variable
rate_equation = ... # Choose a fitting model here.
## Task: Fit to the data at 25 C
fitted_parameters_25C, trash = curve_fit(rate_equation, ..., ...)
## Task: Fit to the data at 40 C
fitted_parameters_40C, trash = curve_fit(rate_equation, ..., ...)
## Extracts & prints the parameters
k_25C, A0_25C = fitted_parameters_25C
k_40C, A0_40C = fitted_parameters_40C
print(k_25C, A0_25C)
print(k_40C, A0_40C)Having made the fits we plot it together with the two data series.
## Your task: Calculate the fits using the chosen rate equation &
## the found parameters found during fitting.
## Hint: You should use the 'rate_equation'-function.
t_smooth = np.linspace(0, 0.05, 100)
A_fit_25C = ...
A_fit_40C = ...
fig, ax = plt.subplots()
## Your task: Plot the two fits
ax.plot(t_smooth, A_fit_25C)
ax.plot(t_smooth, A_fit_40C)
## This plots the data sets
ax.plot(df['t_(s)'], df['[A]_(M)_25C'], 'o', label='[A]_25C', color='C0')
ax.plot(df['t_(s)'], df['[A]_(M)_40C'], 'o', label='[A]_40C', color='C1')
## EXTRA: Sets the axis labels and legend.
ax.set_xlabel('t (s)')
ax.set_ylabel('[A] (M)')
ax.legend()You can go back to the cell where you set rate_equation and use another of the three: zeroth_order, first_order, second_order.
Based on your analysis above or by using the plot the created by the next cell determine the reaction order and the units of the rate constant for each of the two reactions.
The function makes the same fits that you made, but makes them all at once and plots the results side by side.
from fysisk_biokemi.utils.deter_reacti_order_activ import make_plot
rate_laws = {0: zeroth_order, 1: first_order, 2: second_order}
make_plot(df, rate_laws)The function ‘make_plot’ is beyond what is expected for this course, however if you are interested you can see the source code for it on github.
With the assumption that the Arrhenius constant \(A\) and the activation energy are temperature independent in the interval measured, use the Arrhenius equation to calculate the activation energy of the isomerization of the compound A.
You can use \(R = 8.314 \times 10^{-3} \ \frac{\text{kJ}}{\text{mol} \cdot \text{K}}\)
You need to derive the correct equation before using Python to calculate the result.
Perform the calculation in the cell below.
activation_energy = ...Assume that a compound R can react with the unprotonated form of Histidine, \(\text{His}\), to form a covalent reaction product, \(\text{P}\): \[ \text{His} + \text{R} \rightarrow \text{P} \]
The protonated form of Histidine, \(\text{HisH}^+\), is in equilibrium with \(\text{His}\):
\[ \text{HisH}^+ \rightleftharpoons \text{His} + \text{H}^+ \]
The pKa value for this acid-base equilibrium is 6.0. Further assume that the total concentration of Histidine, is
\[ [\text{HisH}^+] + [\text{His}] = 10^{-3} \ \text{M} \]
What percentage of Histidine is unprotonated at pH 6.0. What do you notice about the relationship between pH and pKa in this case? (You should not need to do any arithemtic or algebra to answer this exercise.)
## Your task: What percentage is unprotonated?
percentage_unprotonated = ...Determine \([\text{His}]\) at pH 6
## Your task: Assign known value and calculate [His]
total_conc = ...
his_conc = ...
print(his_conc)The reaction equation for the reaction between \(\text{His}\) and \(\text{R}\) is
\[ v = - \frac{d[\text{His}]}{dt} = k \cdot [\text{His}] \cdot [\text{R}] \]
What’s the reaction order?
If \([\text{R}]\) is much higher than \([\text{His}]\), what can then be concluded regarding the order of the reaction?
Show how a new rate constant, \(k'\), can be defined in these conditions. How does \(k'\) depend on \(\text{R}\)?
At pH 6.0 the reaction rate \(v = 1 \ \text{mM}\cdot \text{s}^{-1}\).
Convert the reaction rate to SI-units given in \(\text{M}\cdot \text{s}^{-1}\).
# Your task: Calculate v in SI units M / s
reaction_rate = ...
print(reaction_rate)Use the concentration of \([\text{His}]\) at pH 6 calculated in question (b), the reaction rate from (f) and constant \([\text{R}] = 0.2 \ \text{M}\) to calculate the rate constant \(k\).
## Your task: Set known value and calculate k ##
## Hint: You should use the his_conc and reaction_rate variables ##
R_conc = ...
k = ...
print(k)import plotly
import fysisk_biokemi.widgets as fbw
from fysisk_biokemi.widgets.utils import enable_custom_widget_colab, disable_custom_widget_colab
from IPython.display import display, HTML
enable_custom_widget_colab()fbw.michaelis_menten_demo()Use the widget created by the cell above to answer the following the questions.
Setting \(V_\mathrm{max} = 400\) and \([E]_\mathrm{tot} = 0.0005\), change \(K_M\) from 0.5 to 5 to 10 to 50. Describe the change in curve appearance and explain it using the Michaelis-Menten (MM) equation.
What is the biochemical meaning of \(K_M\)?
Now set \([E]_\mathrm{tot} = 0.0005\), and \(K_M = 5\). Change \(V_\mathrm{max}\) step-wise from 40 to 900. Describe the changes you observe and how they relate to the MM equation.
After this, repeat the procedure for \([E]_\mathrm{tot}\) increasing it 10-fold.
Next, we will explore the regime where \([S] \ll K_M\). Initially, set \(K_M = 10\) and zoom in on the regime from \(0\) to \(1\) on the X-axis. What does the MM equation look like in this regime? Use the MM equation and a simplifying assumption to show how this occurs.
Next, increase \(K_M\) five-fold and try to change \(V_\mathrm{max}\) som the curve appearance is unchanged (beware of the autoscaling Y-axis).
Imagine an experiment conducted using only \([S]\) values from this range. How would this affect how well you could determine the MM parameters?
Train your estimation skills using the widget below.
fbw.michealis_menten_guess()import matplotlib.pyplot as plt
from scipy.optimize import curve_fit
import numpy as np
import pandas as pd
from fysisk_biokemi.widgets import DataUploader
from IPython.display import display
pd.set_option('display.max_rows', 6)We have finally arrived at the part of the course where we are ready to analyse the data from your lab exercise in the first quarter. First, however we will analyse a similar data set where we are sure about the data quality (😉) to illustrate the process.
In the Excel document design-enzyme-kineti-exper.xlsx you will find a data set in which an enzyme catalyzed formation of product P, with varying start concentration of substrates, [S], was followed over time. The product absorbs light at a specific wavelength with an extinction coefficient of 0.068 \(\mu\text{M}^{-1}\cdot \text{cm}^{-1}\), and the absorbance was measured in a light path of 1 cm throughout the time course.
You can load the dataset using the cells below;
uploader = DataUploader()
uploader.display()Run the next cell after uploading the file
df = uploader.get_dataframe()
display(df)The headers, like Abs_S1 refer to the substrate concentration so S1 means a substrate concentration of 1 \(\mu\text{M}\).
Convert the extinction coefficient to units given in \(\text{M}^{-1}\cdot \text{cm}^{-1}\) and assign it to a variable. Also assign the light path length to a variable.
## Your task: Assign known values in SI units.
...
...Using Lambert-Beers law, calculate the concentration of product, \([P]\), in \(\text{M}\) for each time series.
The cell below setups a loop calculate the concentrations for each of these current columns in the dataframe.
## Your task calculate the concentration for each 'Abs_SX' column and add it ##
## as a new column.
df['C_S1'] = ...
df['C_S2'] = ...
df['C_S4'] = ...
df['C_S8'] = ...
df['C_S16'] = ...
df['C_S32'] = ...
df['C_S64'] = ...
df['C_S128'] = ...
df['C_S256'] = ...And we can check that the columns we expect have been added to the DataFrame.
display(df)We focus now on the C_S32-column and plot it versus the time measurements.
fig, ax = plt.subplots()
## Your task: Plot the C_S32 column
ax.plot(df['time_(s)'], df['C_S32'])
## EXTRA:
ax.set_xlabel('Time (s)')
ax.set_ylabel('Concentration (M)')In enzyme kinetics, we usually focus on the initial time points, i.e. before the reaction has progressed far enough to allow products to be accumulated and substrate to be depleted. In this early stage of the reaction, we know that the concentration has not changed significantly yet and thus the [S] = S0. Therefore, the reaction time course tends to be linear in this range.
In the following, we want to just fit the initial part of the curve. We do this by defining a new data array containing only the first values.
We want to use Python to determine \(V_0\) for each concentration of \(S\), in order to create a table of \(V_0\) vs \([S]\). To do so we will fit linear functions to the initial parts of the curves, as the slope of these is then \(V_0\).
Start by defining a linear function;
def linear_func(x, a, b):
## Your task: Finish implementing the linear function
return ...As mentioned we want to to get the slope in the initial part of the reaction, where the curves are approximately linear. To do so we need to fit not on all the data-points but only some of them.
We will first do this for the C_S32-column.
## Determine the x and y data
x_data_full = df['time_(s)']
y_data_full = df['C_S32']
## Your task: Set n_points to choose the number of points to fit with.
n_points = ...
x_data = x_data_full[0:n_points] # This picks the first n_points points.
y_data = y_data_full[0:n_points] # This picks the first n_points points.
## Your task: Make the fit.
fitted_parameters, trash = curve_fit(..., ..., ...)
a, b = fitted_parametersThe cell below plots your fit alongside the data
fig, ax = plt.subplots()
t_smooth = np.linspace(0, 20)
y_fit = linear_func(t_smooth, a, b)
ax.plot(x_data_full, y_data_full, 'o')
ax.plot(t_smooth, y_fit)
ax.set_xlabel('Time (s)')
ax.set_ylabel('Concentration')You want the line to fit well with the initial approximately linear part of the data, adjust n_points such that this is the case.
In the cell below n_points again determines the number of data-points used for the linear fit, and makes the fits and plots for every dataset.
from fysisk_biokemi.utils.design_enzyme_kineti_exper import make_fits_and_plots
## Your task: Select a number of points to fit with that is appropriate in
## all cases
n_points = ...
## This function does what you did in the previous exercise but for all the datasets. ##
slopes, concentrations = make_fits_and_plots(df, n_points)The function ‘make_fits_and_plots’ is beyond what is expected for this course, however if you are interested you can see the source code for it on github.
Once you’re satisfied with the fit you can display the collected slopes with the cell below
V0_df = pd.DataFrame({'[S]_(M)': concentrations, 'V0_(M/s)': slopes})
display(V0_df)Why is it important to use \(V_0\) rather than \(V\) at a later time point when creating the Michaelis-Menten plot?
Plot \(V_0\) against substrate concentration and estimate \(k_{cat}\) and \(K_M\) visually (remember units)
fig, ax = plt.subplots()
# Your task: Plot the V0_(M/s) versus [S_(M)]
...Use the figure to estimate the value of \(K_M\) and \(V_\text{max}\) and put those in the cell below.
# Your task: Put your estimated values here:
K_M_estimate = ...
V_max_estimate = ...Now we can fit with the Michealis-Menten equation, as always in a fitting task we need to implement the model.
def michaelis_menten(S, K_M, V_max):
## Your task: Implement the Michaelis-Menten model.
result = ...
return resultThen use the next two cells to make the fit and plot it.
## Uses your estimate as initial guess
initial_guess = [K_M_estimate, V_max_estimate]
fitted_parameters, trash = curve_fit(michaelis_menten, V0_df['[S]_(M)'], V0_df['V0_(M/s)'], initial_guess)
## Extract and prints the parameters
K_M_fit, V_max_fit = fitted_parameters
print(K_M_fit)
print(V_max_fit)How do these compare to your estimates of the two parameters?
fig, ax = plt.subplots()
## Evaluates the fit
S_smooth = np.linspace(0, 0.0003, 100)
V0_fit = michaelis_menten(S_smooth, K_M_fit, V_max_fit)
## Plots the fit and the data.
ax.plot(S_smooth, V0_fit)
ax.plot(V0_df['[S]_(M)'], V0_df['V0_(M/s)'], 'o')
## Axis labels.
ax.set_xlabel('[S] (M)')
ax.set_ylabel('$V_0$ (M/s)');import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy.optimize import curve_fit
from fysisk_biokemi.widgets import DataUploader
from IPython.display import displayIn the “Introduction to the Molecules of Life” course, you performed an experiment where you measured absorption for different substrate concentrations as a function of time. The experiment was done with p-nitrophenylphosphate as the substrate, which turns into p-nitrophenol when the enzyme (alkaline phosphatase) acts on it.
If you do not have data, or you find that your data set is not of sufficient quality, you can use the following kinetics_data.xlsx.
Load your dataset using the widget below
uploader = DataUploader()
uploader.display()Run the next cell after uploading the file
df = uploader.get_dataframe()
display(df)The measured absorbances are unitless, they are the log of the ratio between the incoming light intensity and the transmitted light intensity. We would like to work with concentrations instead, so we need to convert the absorbance to concentration. The conversion is done using Lambert-Beer’s law.
The extinction coefficient of the product p-nitrophenol is \(\varepsilon = 18000 \, \text{M}^{-1} \text{cm}^{-1}\) at \(405 \ \text{nm}\) and the path length of the cuvette is \(l = 1\, \text{cm}\). We will construct a new DataFrame with concentrations
We will start by defining a function lambert_beers to calculate the concentrations
def lambert_beers(absorbance):
## Your task: Finish the implementation of LBs-law to calculate concentrations.
L = ... # Units: cm
ext_coeff = ... # Units: 1 / (M cm)
conc = ... # Units: M
return concThe next cell makes a new DataFrame by applying the lambert_beers function to every column in the original
data = {
'time': df['time'],
'S_0.8_mM': lambert_beers(df['0.8']),
'S_0.4_mM': lambert_beers(df['0.4']),
'S_0.2_mM': lambert_beers(df['0.2']),
'S_0.12_mM': lambert_beers(df['0.12']),
'S_0.05_mM': lambert_beers(df['0.05']),
'S_0.02_mM': lambert_beers(df['0.02']),
'S_0.01_mM': lambert_beers(df['0.01']),
'S_0.003_mM': lambert_beers(df['0.003']),
}
df = pd.DataFrame(data)
display(df)Now let’s plot the data. Plot each column separately as a function of time.
fig, ax = plt.subplots()
# Your task: Plot concentration vs. time for each column of the dataset,
# So 8 lines of code total.
...
## Sets the x and y axis labels.
ax.set_xlabel('Time [s]')
ax.set_ylabel('Concentration [M]')
ax.legend()
plt.show()In order to apply the Michaelis Menten equation we need the slopes of these curves as that is the reaction velocity \(V_0\), luckily we have learned how to make fits! So we make a fit to the linear function to determine the slope \(a\) in, \[ y(x) = a x + b \] As always, start by writing the function
Now we want to find the slope for each column, to help with that we will introduce a function that takes the time column and one of the concentration columns and returns the slope
def find_slope(time_data, abs_data):
## This selects the times and absorbances that have been measured (not NaN)
## Don't worry about this - this is just to help you with this exercise.
indices = np.where(~abs_data.isna())[0]
time_data = time_data[indices]
abs_data = abs_data[indices]
# Find the slope and the intercept using curve_fit and return the slope
fitted_parameters, trash = ...
slope = fitted_parameters[0]
return slopeNow we want to use this for each set of measurements at different substrate concentrations.
## Your task: Find the slopes for every substrate concentration.
slope_08 = ...
slope_04 = ...
slope_02 = ...
slope_012 = ...
slope_005 = ...
slope_002 = ...
slope_001 = ...
slope_0003 = ...
## This gathers the slopes and makes an array with the substrate concentrations.
substrate_concentrations = np.array([0.8, 0.4, 0.2, 0.12, 0.05, 0.02, 0.01, 0.003]) * 10**(-3) # Converted from mM to M.
slopes = np.array([slope_08, slope_04, slope_02, slope_012, slope_005, slope_002, slope_001, slope_0003])Now make a plot of the slopes versus the substrate concentrations using the two arrays substrate_concentrations and slopes.
fig, ax = plt.subplots()
## Your task plot the slopes vs. substrate concentration.
...
## Sets x and y axis labels.
ax.set_xlabel('Substrate concentration')
ax.set_ylabel('Slope')
plt.show()## Your task: Estimate K_M and V_max from the plot.
K_M_estimate = ...
V_max_estimate = ...Now that we have the slopes we can fit to the Michaelis Menten equation, again we need to implement the equation
def michaelis_menten(S, K_M, V_max):
## Your task: Implement the Michaelis-Menten model.
result = ...
return resultThen fit to the slopes we extracted to the Michealis-Menten equation
## This is your estimates as the initial guess.
initial_guess = [K_M_estimate, V_max_estimate]
## Your task: Make a fit to the Michaelis-Menten equation & extract K_M and V_max.
fitted_parameters, trash = ...
K_M_fit, V_max_fit = ...
print(K_M_fit)
print(V_max_fit)S_smooth = np.linspace(0, substrate_concentrations.max())
V0_fit = ...fig, ax = plt.subplots()
## Your task: Plot the data and the fit
...
## These add x and y axis labels.
ax.set_xlabel('Substrate concentration (M)')
ax.set_ylabel('$V_0$ (M/s)')
plt.show()Given that the enzyme concentration was \(3.33 \frac{\text{mg}}{\text{L}}\) and the molecular weight of the enzyme (alkaline phosphatase) is 86000 \(\frac{\text{g}}{\text{mol}}\), calculate the turnover number \(k_{cat}\).
Start by converting the enzyme concentration to molar units and then calculate the turnover number.
## Your task: Calculate the enzyme concentration and use that and your fit to
## calculate kcat.
enzyme_conc = ...
kcat = ...
print(kcat)